Home | Introduction | Metadata | Application | Further reading | Landscape of resources |
Introduction
- Challenges for Clinical data and why this guide will help
- How the FAIR principles can bring value to Clinical data
Challenges for Clinical data and why this guide will help
Who this guide is designed for
This guide primarily focuses on data practitioners in the clinical field such as clinical data managers or analysts. The secondary audience are data practitioners in (a) the research domain interested in the clinical and healthcare domain, such as research and registry data curators, terminology managers or bioinformaticians or (b) the post authorization domain, i.e. medical affairs, market access with the interest to compare clinical results with real-world outcomes.
Since clinical trial and health care data is particularly determined by regulatory requirements or healthcare processes respectively, this guide is of interest for employees in pharmaceutical companies, healthcare organisations such as hospitals or medical centres and clinical regulators such as the FDA and EMEA.
Context of this guide: Clinical Data Challenges and Opportunities
We are faced with the tremendous challenge of realising the full value of clinical and healthcare data and associated metadata. This challenge is caused by the complexity and diversity of clinical data types and clinical standards, combined with the sheer volume of clinical data (see section Clinical study data can be big!) and regulatory requirements. Additionally, this data is often locked away in proprietary containers which limit or prevent access and reuse.
Clinical data re-use beyond the primary intent of collection is challenging also for regulatory implementation which protects patient data and limits what can currently be done, and how, with clinical data. On the one hand patient’s privacy must be protected but on the other hand also their wish to share some of their data to enable new and better therapies should be respected. An additional challenge to be met is to protect but also to promote public health through data.
Drug repurposing efforts in the crisis of the COVID-19 pandemic (e.g. Vodan) illustrate the urgent needs and persisting challenges of reusing clinical trials and healthcare data to generate insights. Being able to search, retrieve and integrate data from different clinical trials and to link it to Real World Evidence (RWE) is critical to success. Furthermore, interoperability is crucial when clinical study data needs to be integrated and connected across different clinical studies.
Time is of the essence to bring valuable therapies to market as soon as possible to address unmet needs for patients. Innovative pharmaceutical companies also have a commercial interest to shorten the development times as much as possible. The immense cost and vital importance of clinical data are a motivation - if not an obligation - to make this data FAIR, which means: Findable, Accessible, Interoperable and Reusable by humans as well as machines.
Purpose of this guide: From Awareness to Making Pragmatic Choices
The importance of the FAIR principles [Wilkinson et al. 2016] is well recognised amongst researchers in academia and industry, but its implementation is not yet mature in the clinical domain [Kubben et al. 2019]. This guide aims to raise awareness of the value of FAIR clinical data. It is designed to facilitate pragmatic decision making based on FAIR clinical data and metadata management, which is addressed in Section 2 (Metadata). Topics such as data governance and additional facets of data management such as quality and training are presented in Section 3 (Application). The best practices in data management (“bottom-up”) and strategic data governance (“top-down”) are foundational for achieving a deeply integrated data-centric culture to serve communities of users and stakeholders in the life science industry.
Scope of this guide
This first version of the guide focuses on overcoming the challenges found when implementing the FAIR principles related to data and its metadata for clinical trial and real world evidence. This guide is currently focussed on the clinical study level, rather than patient level, and it is limited to human derived clinical data. We define the clinical study level as 1) result summary data (NOT patient data) and 2) the associated metadata, the study description and protocol. In particular, we will present numerous opportunities for the implementation of the FAIR guiding principles.
Clinical study studies include those generated by the different phases of double blind, controlled trials, prior to product launch. These have been designed primarily to demonstrate efficacy and safety for a new treatment being submitted to the regulatory authorities for drug approval. This guide also addresses clinical studies collected from patients for clinical care purposes and/or in observational studies, commonly referred to as Real World Data (RWD). FAIR implementation is an enabler to realise far greater value from such clinical studies, beyond their primary purpose. For instance, added value may include re-purposing of a medical treatment
Clinical study data can be big!
Big data dimensions include Volume, Velocity, Variety, Value, Veracity and Variability [Ristevski et al. 2018]. Most relevant for this guide are the dimensions of Veracity and Variability as these clearly relate to the semantics (i.e. meaning) and, thereby, the interpretation of clinical data. FAIRifying data is mostly concerned with identifiers and capturing relevant metadata. Therefore this guide focuses more on the variability and veracity of the metadata values rather than the data itself.
The way clinical studies are conducted often leads to a fragmentation of datasets, because of unharmonised metadata - which promulgates issues with data variety and veracity. Consistent FAIR metadata at the study level could reduce such fragmentation. Currently the way clinical studies are represented must comply with the Clinical Data Interchange Standards Consortium (CDISC) Study Data Tabulation Model (SDTM) or Analysis Data Model (ADaM), but the focus is not on FAIR metadata elements nor metadata values. For example, “tagging” of terms in a Rheumatoid Arthritis study from an appropriate ontology e.g. NCIT will enable access to synonyms, and cross-references, which results in semantically stronger metadata.
It is important to maximise the value of clinical trial data once the study is completed rather than locking them away in data silos after the trial is completed. These silos often emerge because clinical trial study data is generated only for its primary purpose, submitting data to regulators in unFAIR formats for drug approvals rather than in a FAIR representation facilitating reusability. Furthermore, a clinical FAIR data management plan can define dataset models for data collection based on the regulatory requirements. There is a risk that these dataset models do not capture all variables which might be of interest for secondary usage.
Clinical raw data can consist of very large datasets at the patient level. However, at the study level, the datasets are considerably smaller, which is the scope of this guide because this is where we currently see the most value for implementation of the FAIR guiding principles (see also Figure 1). For this reason, data volume is not considered a challenge in the context of this first version of the guide.
A multiplicity of clinical data types
The complexity of clinical studies leads to heterogeneity of clinical data types. Clinical data typically falls into one of two categories: operational (anything to do with setting or running the study), or scientific (the actual observations used to test the hypothesis the study was trying to answer).
This complexity can be alleviated to a certain extent by the implementation of the FAIR guiding principles, in combination with appropriate clinical standards, that are developed and supported by standards developing organisations (SDO) such as CDISC, Health Level 7 (HL7) or Observational Health Data Sciences and Informatics (OHDSI).
Further we could classify clinical data into intervention-based from clinical trials and observation-based from healthcare, as generated in hospitals (see also here).
Interventional data
Intervention-based data contains clinical trial data from phases 1, 2 and 3 of clinical trials, which are conducted prior to product launch and phase 4 data collected after the product launch.
Example clinical data standard - CDISC
Some of the Clinical Data Interchange Standards Consortium (CDISC) standards are mandated by the clinical regulators for intervention-based clinical data at study and patient level as well as result summaries. For example the Study Data Tabulation Model (SDTM) is one of the required standards for data submission to FDA (U.S.) and PMDA (Japan). For some priority disease areas (e.g. breast cancer), so-called therapeutic area specific extensions refine the foundational standards and supporting “SDTM implementation guidelines” and “therapeutic area user guides” are available from CDISC. Patient reported outcomes can be a challenge to standardise and thus to interpret. For the most part they can be converted to the SDTM Questionnaire domain, but not always.
Observational data
Observation-based data includes studies for generation of Real World Evidence, initiated by investigators, including translational studies and self-reported patient data or patient-generated health data (PGHD), e.g. from wearable devices. Such observation-based data can bring challenges which could be alleviated through FAIR implementation. For example, observational studies do not have to comply with any (regulatory) standards - though eventually submissions will have to. FAIR can improve the data structure to make datasets more ready for analysis. As a further example, a variety of code dictionaries (e.g. ICD, SNOMED, ATC, NDC) are often used in different healthcare systems to standardise data which can make it difficult to compare data from different data sources.
Example observation-based data standard - OMOP/OHDSI
The OHDSI (pronounced “Odyssey”, is Observational Health Data Sciences and Informatics) standard supports the harmonisation of observation-based patient data collected during routine clinical practice with the purpose to perform systematic studies across disparate observational healthcare databases (see also the OMOP record in FAIRsharing and the OHDSI vocabularies record in FAIRsharing).
Real World Data
Real World Data (RWD) summarises data from countless sources like EHRs, GPs, registries and insurance claims databases etc. RWD can be intervention or observation-based. The FDA defines such RWD as “the data relating to patient health status and/or the delivery of health care routinely collected from a variety of sources” (see here for examples).
Examples of RWD sources include:
- Routinely collected healthcare data from hospitals and primary care sites. This can be directly from the EHR systems or from insurance claims.
- Often highly standardised to local and/or national coding standards. There is a slow shift to using international standards like SNOMED or ICD and many initiatives to map national to international codings (e.g. by EU IMI EHDEN).
- Not collected for research purposes. Large biases might exist in the data and should be corrected for.
- Hard to get access as the data is very privacy sensitive.
- Data from wearable sensors
- Medical grade devices vs Consumer grade devices
- Patient reported outcomes (e.g. Data from social media sources))
Example RWD standard - FHIR
The Fast Healthcare Interoperability Resources (FHIR, pronounced “fire”) is a global standard for passing healthcare data between systems. It describes data formats and elements, known as “resources”, and an application programming interface (API) for exchanging Electronic Health Records (EHR). FHIR can support both interventional and observational clinical data at the study, results summary and patient levels; see also FHIR record in FAIRsharing. This is addressed further in Section 2 of the guide.
Other clinical data standards
There are many other clinical standards for observation-based clinical data besides the three standards mentioned above as these are the most common ones. Examples for other standards include openEHR and i2b2/tranSMART. One can find other relevant standards at FAIRsharing, but please note as different studies could be reported in different formats, it is important to handle this diversity by creating connectors between standards and integration methodologies.
How the principles FAIR can bring value to Clinical data
We have already described the two major sources of clinical data from clinical trials and routine clinical practice (i.e. real-world). The value of such clinical data would be greatly increased through FAIR Implementation which will likely include the application of interoperability standards such as CDISC, FHIR and vocabularies which are mandatory for submission to the regulators. FAIR data and metadata from clinical trials and real world sources are more likely to be ready for consumption by machine learning and semantic knowledge graphs which will support secondary reuse over much greater periods, as illustrated in figure 1. This would require the use of mappings to strong semantic standards at data capture time, such as proper use of SNOMED-CT or openEHR archetypes.
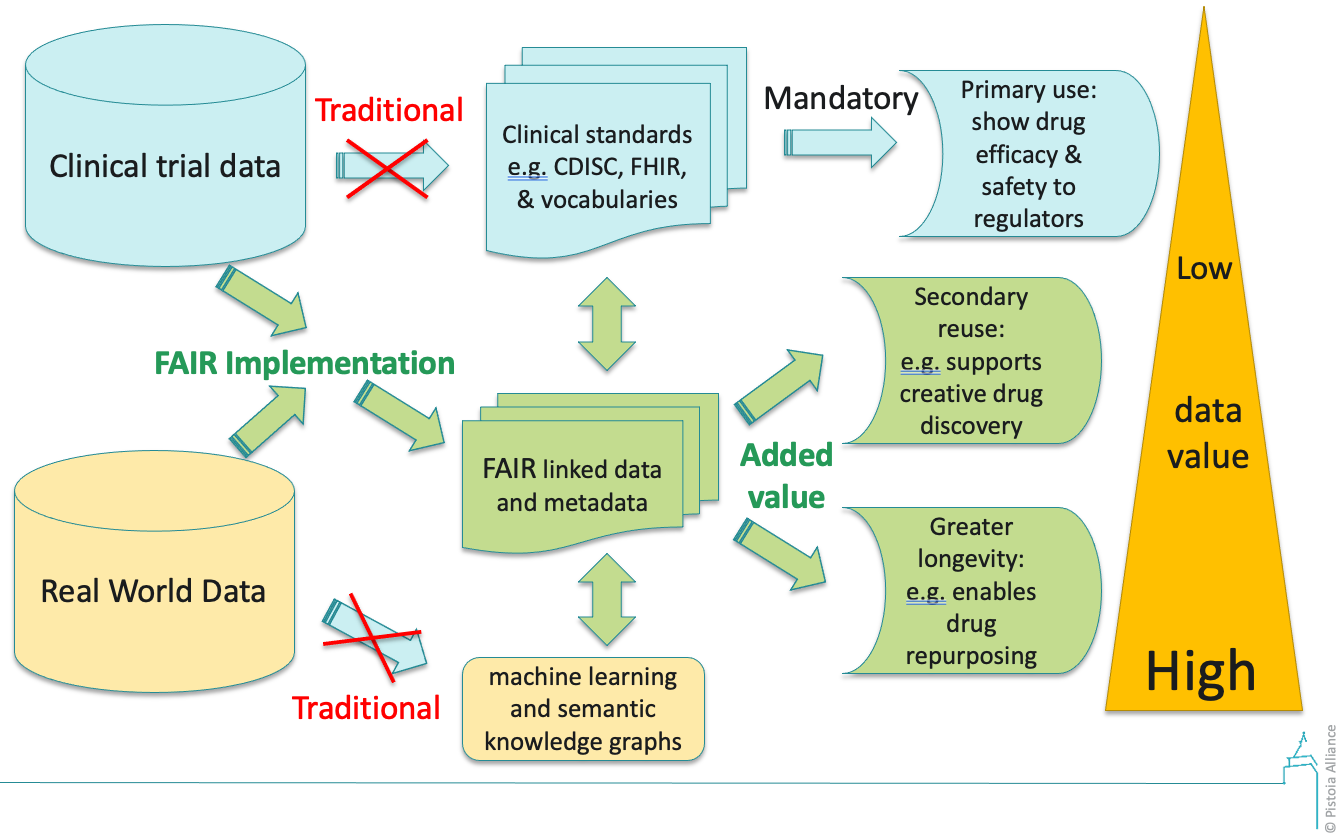 Figure 1: Increasing the value of clinical data through FAIR Implementation, breaking up data silos and enhancing flexibility and reusability. The traditional paths (blue arrows) are with no implementation of FAIR. When FAIR is implemented the traditional paths become obsolete and (blue arrows crossed out). FAIR implementation is central to generation of FAIR linked data and metadata which supports the ‘added value’, indicated in green.
Figure 1: Increasing the value of clinical data through FAIR Implementation, breaking up data silos and enhancing flexibility and reusability. The traditional paths (blue arrows) are with no implementation of FAIR. When FAIR is implemented the traditional paths become obsolete and (blue arrows crossed out). FAIR implementation is central to generation of FAIR linked data and metadata which supports the ‘added value’, indicated in green.
Realising value for clinical trial data
Pharmaceutical companies conduct clinical trials at great expense, primarily to demonstrate to the regulatory authorities that new treatments are efficacious and safe. Although data standards such as CDISC are mandatory for clinical trial submission to FDA, this does not make data FAIR (as will be shown in section 2) and in fact, could actually limit future reuse. However, if clinical data were FAIRified first, this would unlock much more value (see figure 1). Besides making clinical study data and metadata more Findable, Accessible and Reusable it would also benefit from much greater Interoperability. This semantic enrichment of clinical study data will enhance its value both within a company and outside, when it is shared with external parties, including public registries such as clinicaltrials.gov.
The dynamics of realising value can take account of expected timings. Within an organisation, the value is likely to be in the short to intermediate time scales. For the short term (1-2 years), the effectiveness and speed of electronic data capturing is improved by including the most relevant clinical vocabularies or ontologies for a particular clinical trial study. Interoperability through FAIR clinical vocabularies or ontologies could accelerate data integration and interpretation. Time is critical for this primary usage. In the medium term (2-3 years), it is possible to gain much more value from the clinical data beyond immediate primary usage. Findability, Accessibility and Reuse of clinical data will enable future secondary analysis.
This compares with the value expected for the medium to long term (3-5 years) for sharing data with external parties, such as business partners and public registries, like http://clinicaltrials.gov. FAIR implementation for clinical data will enhance its acquisition, sharing and integration as shown in Table 1.
Table 1: Summarising the expected value of data FAIRification.
| Value of data and metadata | Short term | Medium term | Long term |
|---|---|---|---|
| Within an organisation | x | ||
| For external partners | x | x |
Realising value from Real World Data
Here are some qualitative examples of how to leverage Real World Data (RWD), by integrating them with other data types (e.g. by unlocking the insights contained in genomic and phenotypic data), can generate value and help all key stakeholders in the healthcare ecosystem.
- RWD can help to identify and satisfy unmet needs in Biopharmaceutical Research and Development, such as to inform research decisions; innovate/improve clinical trial design by using synthetic control arms; help defining inclusion-exclusion criteria and end-points; optimise site selection, accelerate recruitment; overall reducing time to market; monitor real world outcomes by quantifying unmet needs and understanding safety and efficacy profiles.
- RWD accelerates the demonstration of economical value of treatment to payers; enables outcome-based pricing; makes it possible to achieve label expansion, by eliminating the need for randomised controlled trials.
- RWD analysis provides the clinical evidence, i.e. Real-World Evidence (RWE), regarding the usage and potential benefits or risks of a medical product. This will improve pharmacovigilance by monitoring real world usage and adverse effects; helping to create quickly risk / benefit overviews. This may strengthen the need for differentiation and inclusion to help highlight the benefits or risks for under-studied populations, or could be useful for investigations on rare diseases.
Overall RWD can help to improve adherence supporting personalised approaches with engagement techniques such as Electronic Patient Reported Outcomes (e-PROs) and other digital interventions.
